
20 March 2024
APACHE SPARK – Best Practices

Apache Spark is a Big Data tool that processes large datasets in a parallel and distributed way. It is an extension of the already known programming model from Apache Hadoop—MapReduce—that facilitates the development of processing applications for large data volumes. Spark reveals much superior performance compared to Hadoop, as in some cases, it reaches a performance of almost 100x bigger.
Another advantage is that all components work integrated within the same framework, like Spark Streaming, Spark SQL, and GraphX, unlike Hadoop, where it is required to use tools that integrate with it but are distributed separately, like Apache Hive. Another important aspect is that Spark can be programmed in four different languages: Java, Scala, Python, and R.
Spark has several components for different types of processing, all built on Spark Core, which is the component that offers the basic functions for the processing functions like map, reduce, filter and collect:
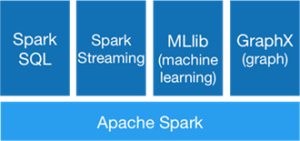
Fig 1. Apache Spark Components
This section will explain the primary functionalities of Spark Core. First, it will show the application architecture and then the basic concepts of the programming model for data dataset processing. Spark application architecture is constituted by three major parts:
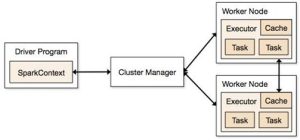
Fig 2. Spark Architecture
Apart from the architecture, it is important to know the principal components of the programming model from Spark. There are three fundamental concepts that will be used in all developed applications:
Because of the in-memory nature of most Spark computations, Spark programs can be bottlenecked by any resource in the cluster: CPU, network bandwidth, or memory. Most often, if the data fits in memory, the bottleneck is network bandwidth, but sometimes it is required to do some tuning. In this section, we will show some techniques for tuning Apache Spark for optimal efficiency:
A memory exception will be thrown if the dataset is too large to fit in memory when doing an RDD.collect(). Functions like take or takeSample are sufficient to get only a certain number of elements instead.
Rather than return the exact number of rows in the RDD, you can check if it is empty with a simple if(take(1).length == 0).
There are two functions, reduceByKey and groupByKey, and both will produce the same results. However, the latter will transfer the entire dataset across the network. At the same time, the former will compute local sums for each key in each partition and combine those local sums into larger sums after shuffling.
Below is a diagram to understand what happens with reduceByKey. There is more than one pair on the same machine with the same key being combined before the data is shuffled.
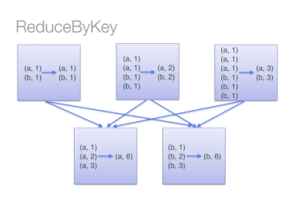
Fig 3. ReduceByKey
On the other hand, when calling groupByKey – all the key-value pairs are shuffled around. This is many unnecessary data being transferred over the network.
To determine which machine to shuffle a pair to, Spark calls a partitioning function on the pair’s key. Spark spills data to disk when there is more data shuffled onto a single executor machine than can fit in memory. However, it flushes out the data to disk one key at a time, so if a single key has more key-value pairs than can fit in memory, an out-of-memory exception occurs.
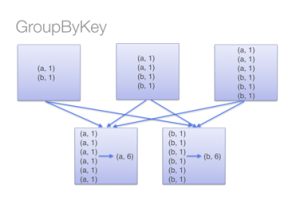
Fig 4. GroupByKey
Shuffling can be a great bottleneck. Having many big HashSets (according to your dataset) could also be a problem. However, it is more likely that you will have a large amount of ram than network latency, which results in faster reads/writes across distributed machines.
Here are more functions to prefer over groupByKey:
When two datasets are already grouped by key, and you want to join them and keep them grouped, you can just use cogroup. That avoids all the overhead associated with unpacking and repacking the groups.
Use the coalesce function if you decrease the number of partitions of the RDD instead of repartition. Coalesce is useful because it avoids a full shuffle. It uses existing partitions to minimize the amount of data that is shuffled.
Spark computes the task’s closure before running each tasks on the available executors. The closure is those variables and methods which must be visible for the executor to perform its computations on the RDD. If there is a huge array that is accessed from Spark Closures, e.g. some reference data, this array will be shipped to each spark node with closure. For instance, if we have 10 nodes cluster with 100 partitions (10 partitions per node), this Array will be distributed at least 100 times (10 times to each node). If broadcast is used it will be distributed once per node using efficient P2P protocol. Once the value is broadcasted to the nodes, it cannot be changed to make sure each node have the exact same copy of data. The modified value might be sent to another node later that would give unexpected results.
If the small RDD is small enough to fit into the memory of each worker, we can turn it into a broadcast variable and turn the entire operation into a map-side join for the larger RDD. This way, the larger RDD does not need to be shuffled at all. This can easily happen if the smaller RDD is a dimension table.
If the medium-size RDD does not fit fully into memory but its key set does, it is possible to exploit this. As a join will discard all elements of the larger RDD that do not have a matching partner in the medium size RDD, it can be used the medium key set to do this before the shuffle. If there is a significant amount of entries that get discarded this way, the resulting shuffle will need to transfer a lot less data. It is important to note that the efficiency gain here depends on the filter operation actually reducing the size of the larger RDD.
Unless the level of parallelism for each operation is high enough, clusters will not be fully utilized. Spark automatically sets the number of partitions of an input file according to its size and for distributed shuffles. Spark creates one partition for each block of the file in HDFS with 64MB by default. When creating an RDD it is possible to pass a second argument as a number of partitions, e.g.:
val rdd= sc.textFile(“file.txt”,5)
The above statement will create an RDD of textFile with 5 partitions. The RDD should be created with the number of partitions equal to the number of cores in the cluster in order for all partitions to be processed as parallel and resources to be used equally.
DataFrame creates a number of partitions equal to spark.sql.shuffle.partitions parameter. spark.sql.shuffle.partitions’s default value is 200.
yarn.nodemanager.resource.memory-mb = ((Node’s Ram GB – 2 GB) * 1024) MB
Total Number of Node’s Core = yarn.nodemanager.resource.cpu-vcores
For the executorMemory the memory allocation is based on the algorithm:
Runtime.getRuntime.maxMemory * memoryFraction * safetyFraction, where memoryFraction = spark.storage.memoryFraction and safetyFraction = spark.storage.safetyFraction.
The default values of spark.storage.memoryFraction and spark.storage.safetyFraction are respectively 0.6 and 0.9 so the real executorMemory is:
executorMemory = ((yarn.nodemanager.resource.memory-mb – 1024) / (Executor (VM) x Node +1)) * memoryFraction * safetyFraction.
Consider the following example:
3 Worker nodes and one Application Master Node each with 16 vCPUs, 52 GB memory
yarn.nodemanager.resource.memory-mb = (52 – 2) * 1024 = 51200 MB
yarn.scheduler.maximum-allocation-mb = 20830 MB (must be greater than executorMemory)






