
7 March 2024
Approaching the Modern Data Stack

What business data points are you blind to? What’s the potential left on the table with the data that you’re not storing? What relationship, short and long term, do you want with the technology that can remove these blind spots – rely on a provider, a consultancy company, or staff up internally?
TL;DR: there is not one (easy) path, or we might be out of a job.
With the abundance of data sources – from ERPs and CRMs to social media and IoTs, even start-ups and non-tech businesses understand the value of analytics and cloud services in retaining and acquiring new business by better understanding their audience, the potential for more cost-efficient internal processes and, the possibility of automation in their organization.
However, these smaller – or less tech-savvy – organizations will be cautious about developing and maintaining workloads if they are not specialized.
They will rely on a consultancy company (like us!) to develop and maintain their workloads.
They can use that initiative to grow their team internally by actively participating in the development and taking on some, if not all, the future ongoing maintenance and developments.
As a data analytics specialist, every new client means delving deep into their business to assist in building a data analytics roadmap that delivers short term but is also aligned with a long-term organization-wide vision that considers culture, competencies, goals, commitments and chooses the right processes, technology, and development path.
Development is aligned; what about the tools?
Some important points:
What might a managed services data analytics architecture look like initially?
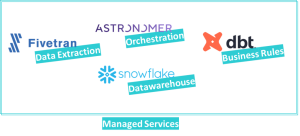
Starting with the Datawarehouse – there is some good competition on the market – Snowflake, Amazon Redshift, and Google BigQuery are popular services offering different features and pricing options. Hence, it’s critical to understand which features you need and determine your usage pattern to assess the right technology.
DBT is a good choice for creating and maintaining your business models. It’s a framework for creating SQL models with features such as data testing, data lineage, documentation, version control, and abstraction layers that make your project modular and flexible. A well-developed DBT project will promote replacing Datawarehouse technologies in the future as it considerably lowers the rework effort.
DBT is an open-source project; however, there is a Cloud offering with competitive pricing for a small development team – all without worrying about hosting!
If you’re using source data from another team or department and it’s already in storage that can be referenced by your Datawarehouse (such as Amazon RDS, Amazon S3, Azure Storage Account or Google Cloud Storage, etc.), then congratulations as your backend data architecture may start with just these two tools.
However, most projects will require extracting new data. In this case, you can use a managed service like Fivetran or Stich, which will work to host and maintain the connectors; you choose the source, the target and pay-per-use.
If you start facing requests such as – “I want specific models to be refreshed right after certain data is extracted and loaded”, “I want to add custom sources that my extraction tool does not support”, or “I need some custom automated steps to connect a few processes during the ELT process”, then you might need to add another layer into your ecosystem, a flexible orchestrator that can oversee the entire process and fill potential missing gaps, such as the Astronomer – which is essentially a managed version of Apache Airflow.
Many other managed tools are available in the market for various use cases, such as cataloguing, testing, and monitoring, that can be added to this architecture.
The more applications you add, you may have a more challenging time managing your developments, integrations and deployments, as each tool may have its own approach.
If this following sentence ever makes sense to you – “My business feature requests are growing, so is my developer team and the workload size, taking me into higher tiers of the managed services which are becoming too expensive – I want to take on some of the maintenance internally and customize my architecture to my exact needs” – then the following architecture aims to address that:
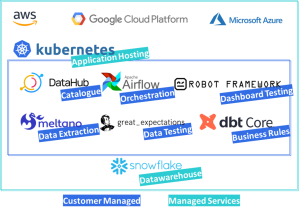
The first objective is to set up a good base infrastructure in any of the clouds that can scale, is well adopted, allows for any application hosting, and has resource efficiency – Kubernetes is the standard to fulfil these requirements (it’s how most managed services work in the backend) as it will host your applications, share cloud resources between them for efficiency and will assure communication among applications and the outside world.
You don’t need to manage “pure Kubernetes”, though, as each cloud has its own managed service for Kubernetes so that part of the maintenance is assured by the cloud provider (like every managed service – for a small fee), and you can add your cloud agnostic workloads inside – a nice compromise between customization, price, features, and maintenance.
After the base infrastructure is setup, you can then install the applications you need, such as Apache Airflow and DBT Core, among others – and refactor the previous workloads from managed services into the new architecture – if the managed services were chosen with a roadmap like this in mind, the refactor of business rules, and process orchestration will be heavily reduced.
Some benefits of this architecture are the pricing at a larger scale, the ease of creating multiple environments quickly and dynamically as needed—such as various dev environments (one for each development or developer) and proper pre-prod environments for better testing and UAT process—and a more centralized CI/CD pipeline.
Before committing to an architecture, many more considerations must occur, as each client will have unique requirements and blockers.
However, one common theme is that business teams want new features delivered faster and faster. The market for data analytics is evolving rapidly, and new and better offerings are continuously being released, so the importance of being adaptable in this marketplace is more significant than ever.






