
10 Setembro 2025
Frameworks orientadas por metadados no Microsoft Fabric: Implementações em YAML (Parte 3)

Este é o último artigo da nossa série sobre frameworks de metadados no Microsoft Fabric. Depois de explorarmos a configuração e o logging, chegamos agora à questão de como fazer a implementação (deployment) segura de ficheiros YAML entre ambientes.
Ao contrário de pipelines, warehouses ou notebooks, os ficheiros de configuração YAML não são artefactos do Fabric. Isto significa que não são incluídos nos pipelines de deployment nativos do Fabric. Assim, as implementações têm de ser orquestradas externamente — no nosso caso com o Azure DevOps. (A mesma abordagem funcionaria também com o GitHub Actions.)
Se estiveres a desenvolver com o VS Code, o processo é simples: crias os ficheiros YAML localmente, validas com o script de validação e fazes commit no controlo de versões. Esta é, em geral, a prática recomendada, porque tiras proveito do linting, validação do schema e controlo de versões no mesmo fluxo.
Mas e se trabalhares apenas dentro da UI do Fabric? Nesse caso, continuas a precisar de uma forma de criar e manter ficheiros de configuração YAML. Como a própria UI do Fabric não oferece um editor nativo para YAML, tens de adicionar os ficheiros de configuração diretamente no repositório através da UI do Azure DevOps (ou da UI do GitHub, se for aí que o teu repositório está).
Em resumo:
O YAML é flexível, mas também notoriamente sensível à indentação e estrutura. Basta um espaço mal colocado para quebrar completamente uma implementação, já que o código que consome o ficheiro espera propriedades muito específicas.
Para reduzir o risco de configurações malformadas chegarem aos ambientes, adicionámos duas salvaguardas antes de qualquer implentação:
1.Validação de esquema
Definimos um JSON Schema ao qual cada configuração YAML tem de obedecer.
Aqui está um excerto simplificado do schema:
Isto garante, no mínimo, que cada ficheiro de configuração declara o nome do modelo, o flag de ativação e define objetos numa das camadas do framework (bronze, silver, gold).
2.Script de validação em Python
Um script verifica todos os ficheiros YAML se estão em conformidade com esse esquema.
Além disso, também executa validações adicionais, como verificação de dependências, lógica de processamento delta e consistência de parâmetros.
Por exemplo, é assim que garante que as dependências entre camadas existem de facto:
Desta forma, se alguém escrever dependsOn: [“silver.MisspelledObject”], a validação falha antes sequer do ficheiro chegar ao DevOps.
O pipeline executa esta verificação antes de qualquer implementação, detetando problemas logo no início.
Dica para developers: ao trabalhar no VS Code, pode correr o script de validação localmente antes de fazer commit. É como um corretor ortográfico para as tuas configurações — só que, em vez de apanhar erros em palavras, apanha lapsos que poderiam deitar abaixo todo o pipeline.
Para manter as diferenças específicas de cada ambiente sob controlo, o projeto está organizado com uma estrutura de pastas clara:
Isto significa que:
Assim, embora o mesmo script de implementação seja executado em todas as fases, os inputs variam por ambiente. Isso permite diferenças controladas (por exemplo, caminhos de origem ou destinos diferentes) sem “hacks” ou ajustes manuais.
Depois da validação ter sucesso, o pipeline avança para o processo de implementação propriamente dito. Estruturámo-lo em quatro fases:
E é assim que se apresenta no Azure DevOps:
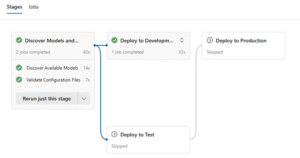
Esta abordagem baseada em fases garante que apenas os YAMLs validados e funcionais chegam aos ambientes superiores.
Um detalhe importante: as localizações dos ambientes (caminhos no OneLake, nomes de workspace, etc.) são armazenadas em variáveis do pipeline. Isto significa que o mesmo script de implementação em PowerShell é reutilizado em todos os ambientes. Sem duplicações, sem “hacks” específicos para cada ambiente — apenas um caminho de promoção limpo do Dev para o Prod, com governança integrada.
Após a validação, a etapa final da implementação é gerida por um script PowerShell que envia os ficheiros de configuração para o OneLake. O script trata de carregar os YAMLs validados para a localização do ambiente apropriado.
Aqui está um excerto simplificado do script:
Como os nomes dos workspaces e os caminhos de destino são passados como variáveis pelo pipeline, este mesmo script funciona sem problemas para Dev, Test e Prod.
Com validação, estrutura de pastas específica por ambiente e um pipeline de implementação em múltiplas fases, as configs YAML são promovidas de forma segura e consistente entre os ambientes.
E com isto, encerramos a série sobre frameworks de metadados:
O que começou como um conjunto de tabelas de configuração dispersas é agora um framework estruturado, validado e automatizado, a funcionar no Microsoft Fabric.






