
22 Mai 2025
Multimodale prädiktive Modelle: Ein praktischer Ansatz in Medizin und Bildung

Im ersten Teil dieses Artikels haben wir uns mit den Grundlagen der multimodalen künstlichen Intelligenz beschäftigt: was sie ist, wie sie funktioniert und die wichtigsten Methoden der Datenfusion. Wir haben uns angesehen, wie multimodale Systeme verschiedene Modalitäten – wie Text, Bild, Sprache oder biometrische Signale – integrieren können, um reichhaltigere, genauere und kontextbezogenere Interaktionen zu schaffen. Wir haben auch die technischen Herausforderungen und Vorteile dieses Ansatzes untersucht, der darauf abzielt, die Wahrnehmungs- und Reaktionsfähigkeiten der KI der Art und Weise anzunähern, wie Menschen mit der Welt interagieren.
In diesem zweiten Teil werden wir die Rolle der multimodalen KI im Gesundheits- und Bildungswesen untersuchen. Beide Bereiche werden nach und nach durch KI verändert, die die Patientenversorgung verbessert und das Lernen personalisiert. Wir werden zwei Beispiele untersuchen, um die Vorteile und Herausforderungen der Implementierung multimodaler KI in diesen Bereichen zu verstehen.
Anwendungsfall 1: Multimodale KI im Gesundheitswesen
Im Gesundheitswesen fallen riesige und vielfältige Daten in unterschiedlichen Formaten an, z. B. medizinische Bilder, klinische Notizen, Labortests und Patientenakten. Die Kombination dieser verschiedenen Datentypen bietet das Potenzial für einen ganzheitlicheren Blick auf den Zustand des Patienten. Multimodale KI-Engines sind darauf ausgelegt, diese verschiedenen Datenquellen zu verarbeiten und zu integrieren, was zu besseren Diagnosen und individualisierten Behandlungsplänen führt.
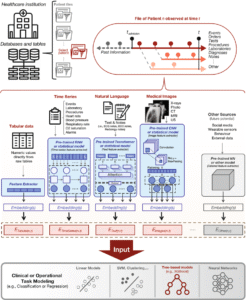
Ein Beispiel dafür, wie multimodale KI im Gesundheitswesen eingesetzt wird, ist das Holistic AI in Medicine (HAIM) Framework. HAIM simuliert ein vielfältiges Set mit unterschiedlichen Datentypen (z. B. EHR, medizinische Bildgebung und klinische Aufzeichnungen), um das prädiktive Modelllernen im Gesundheitswesen zu verbessern. Durch die Integration dieser drei Arten von Datensätzen hat HAIM bessere Ergebnisse für verschiedene Aufgaben gezeigt, darunter die Identifizierung von Krankheiten und die Vorhersage von Patientenergebnissen. Die durchschnittliche prozentuale Verbesserung aller multimodalen HAIM-Vorhersagesysteme liegt bei 9-28 % für alle bewerteten Aufgaben (Integrated multimodal artificial intelligence framework for healthcare applications | npj Digital Medicine).
HAIM kombiniert Daten aus verschiedenen Quellen, um umfassende Patientenprofile zu erstellen. Jedes Profil enthält strukturierte Daten wie demografische Daten, Laborergebnisse und Medikamentenaufzeichnungen, Zeitreihendaten wie Vitalzeichen und andere chronologische Messungen, unstrukturierte Texte wie klinische Notizen und Berichte sowie medizinische Bilder, einschließlich Röntgenaufnahmen und zugehörige Bildgebungsdaten. Jeder Datentyp wird separat verarbeitet, um numerische Darstellungen zu erstellen, die als Einbettungen bezeichnet werden:
Die einzelnen Einbettungen aus jeder Modalität werden zu einer umfassenden Fusionseinbettung zusammengefügt. Diese einheitliche Darstellung dient als Input für prädiktive Modelle wie XGBoost, um Aufgaben wie die Diagnose von Krankheiten und die Vorhersage von Patientenergebnissen durchzuführen.
Vorteile:
Herausforderungen:
Anwendungsfall 2: Multimodale KI im Bildungswesen
Das Bildungswesen ist ein natürlicher Kandidat für multimodale KI, da Lernmaterialien oft eine Mischung aus Text, Bildern, Grafiken und Diagrammen enthalten. Herkömmliche KI-Tools für den Bildungsbereich haben hauptsächlich mit Text gearbeitet, aber durch die Einbeziehung anderer Formen von Inhalten (visuelle und interaktive Elemente) können multimodale Systeme besser widerspiegeln, wie Menschen lernen. Dies führt zu ansprechenderen und effektiveren Lernerfahrungen, die auf die verschiedenen Lernstile zugeschnitten sind.
Eines der vielversprechendsten Beispiele für diesen Ansatz ist das MuDoC-System (Multimodal Document-grounded Conversational AI). MuDoC wurde entwickelt, um Lernende zu unterstützen, indem es die Verarbeitung natürlicher Sprache und Computer Vision kombiniert, um Bildungsmaterialien zu analysieren, einschließlich schriftlicher Texte und visueller Elemente. Wenn ein Schüler eine Frage stellt, antwortet das System nicht nur mit einfachem Text. Stattdessen scannt es das Ausgangsmaterial, sucht den relevanten Abschnitt heraus und liefert eine Antwort, die den erforderlichen Text und die Bilder aus dem Originaldokument integriert. Dies hilft den Lernenden, stärkere mentale Modelle aufzubauen und die Antworten der KI direkt in den Lernmaterialien zu überprüfen, wodurch Transparenz und Vertrauen geschaffen werden.
Technisch gesehen verwendet MuDoC ein Sprachmodell (wie GPT-4o), um Antworten in natürlicher Sprache zu verarbeiten und zu generieren. Gleichzeitig wendet es Computer-Vision-Techniken an, um in Lerndokumenten eingebettete visuelle Inhalte (wie Diagramme, Abbildungen und Illustrationen) zu analysieren. Das System bildet diese verschiedenen Inhaltstypen in einer einheitlichen Darstellung ab, die es ihm ermöglicht, sie kontextabhängig auszuwählen und zu kombinieren. Dieser Prozess führt zu umfassenden, fundierten Antworten, die über das hinausgehen, was rein textbasierte KI-Systeme liefern können. Es entsteht ein dynamischer Lernassistent, der nicht nur erklärt, sondern auch zeigt und so ein besseres Verständnis komplexer Themen ermöglicht.
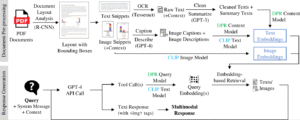
Fig 2. [2504.13884] Towards a Multimodal Document-grounded Conversational AI System for Education
Vorteile:
Herausforderungen:
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass multimodale KI die Art und Weise verändert, wie Maschinen die Welt verstehen und mit ihr interagieren, indem sie Daten aus verschiedenen Quellen wie Text, Bildern, Sprache und Zeitsignalen kombiniert.
Das HAIM-Framework nutzt diesen Ansatz, um umfassende Patientenprofile im Gesundheitswesen zu erstellen und Leistungsverbesserungen zu erzielen, einschließlich Krankheitsdiagnose und Ergebnisvorhersage. Es steht jedoch vor Herausforderungen wie der Notwendigkeit einer anspruchsvollen Datenvorverarbeitung, hohen Rechenanforderungen, strengen Datenschutzmaßnahmen und der Interpretierbarkeit des Modells, die für das klinische Vertrauen und die Skalierbarkeit von entscheidender Bedeutung sind.
In ähnlicher Weise nutzt das MuDoC-System im Bildungsbereich multimodale KI, um das Engagement der Schüler zu erhöhen und das Lernen durch eine Kombination aus Worten und Bildern zugänglicher und verständlicher zu machen. Es muss jedoch die Herausforderungen bewältigen, die sich aus der genauen Abstimmung von Text und Bildern, der Gewährleistung der Zugänglichkeit für alle Lernenden und der Bewältigung hoher Rechenanforderungen ergeben.
Wie im HAIM-Framework und im MuDoC-System zu sehen ist, ermöglicht dieser Ansatz genauere Vorhersagen, tiefere Einblicke und bessere Nutzererfahrungen. Auch wenn es noch Herausforderungen gibt, ist das Potenzial der multimodalen KI zur Verbesserung der Entscheidungsfindung, zur Personalisierung von Erfahrungen und zur stärkeren Angleichung an die menschliche Kommunikation eine wichtige Richtung für die Zukunft der künstlichen Intelligenz.






