
20 Março 2024
APACHE SPARK – Boas Práticas

O Apache Spark é uma ferramenta de Big Data cujo objectivo é processar grandes conjuntos de dados de forma paralela e distribuída. É uma extensão do modelo de programação já conhecido do Apache Hadoop – MapReduce – que facilita o desenvolvimento de aplicações de processamento de grandes volumes de dados. O Spark revela um desempenho muito superior ao do Hadoop, já que, em alguns casos, atinge um desempenho quase 100 vezes superior.
Outra vantagem é que todos os componentes funcionam integrados no mesmo framework, como Spark Streaming, Spark SQL e GraphX, diferentemente do Hadoop, onde é necessário usar ferramentas que se integram nele, mas são distribuídos separadamente, como o Apache Hive. Outro aspeto importante é que o Spark pode ser programado em quatro linguagens diferentes: Java, Scala, Python e R.
O Spark possui vários componentes para diferentes tipos de processamento, todos construídos no Spark Core, que é o componente que oferece as funções básicas para as funções de processamento, como map, reduce, filter e collect:
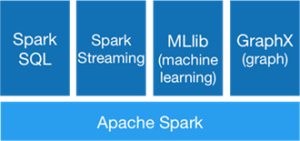
Fig 1. Componentes do Apache Spark
Nesta secção, serão explicadas as principais funcionalidades do Spark Core. Inicialmente será mostrada a arquitetura das aplicações e, em seguida, os conceitos básicos sobre o modelo de programação para o processamento de conjuntos de dados. A arquitetura das aplicações de Spark é constituída por três partes principais:
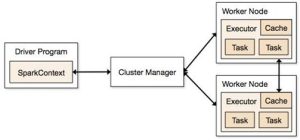
Fig 2. Arquitetura do Spark
Para além da arquitetura, é importante conhecer os principais componentes do modelo de programação do Spark. Existem três conceitos fundamentais que serão usados em todas as aplicações desenvolvidas:
Devido à natureza in-memory da maioria dos cálculos do Spark, os programas Spark podem ser um entrave a qualquer recurso no cluster: CPU, largura de banda de rede ou memória. Na maioria das vezes, se os dados cabem em memória, o entrave é a largura de banda da rede, mas às vezes é necessário fazer algum ajuste. Nesta secção, mostraremos algumas técnicas para ajustar o Apache Spark para uma eficiência ideal:
Uma exceção de memória é lançada se o Dataset for muito grande para caber na memória ao executar um RDD.collect(). Funções como take ou takeSample são suficientes para obter apenas um determinado número de elementos.
Em vez de retornar o número exato de linhas no RDD, é possível verificar se está vazio com um simples if(take(1).length == 0).
Existem duas funções: reduceByKey e groupByKey e ambas produzem os mesmos resultados. No entanto, este último transferirá todo o Dataset pela rede, enquanto o primeiro calcula somas locais para cada chave em cada partição e combina essas somas locais em somas maiores após o shuffle.
Em baixo está um diagrama para entender o que acontece com o reduceByKey. Há mais de um par na mesma máquina com a mesma chave, assim é combinada antes que os dados sejam baralhados.
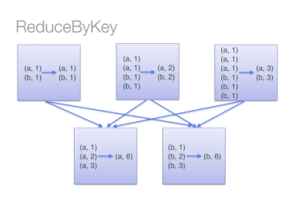
Fig 3. ReduceByKey
Por outro lado, ao chamar groupByKey, todos os pares de key-value são baralhados. São muitos dados desnecessários para serem transferidos pela rede.
Para determinar para qual máquina ocorre o shuffle de um par, o Spark chama uma função de particionamento na chave do par. O Spark envia dados para disco quando há mais dados baralhados num único executor do que os que podem caber na memória. No entanto, ele liberta os dados para o disco uma chave de cada vez – portanto, se uma única chave tiver mais pares de key-value do que pode caber na memória, ocorrerá uma exceção de memória insuficiente.
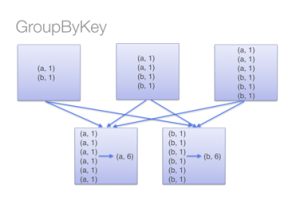
Fig 4. GroupByKey
O shuffle pode ser um grande entrave. Ter muitos HashSet’s grandes (de acordo com o Dataset) também pode ser um problema. No entanto, é mais provável que tenha uma grande quantidade de memória RAM do que a latência da rede, o que resulta em leituras / gravações mais rápidas em máquinas distribuídas.
Aqui estão mais funções com preferência sobre o groupByKey:
Quando dois Datasets já estão agrupados por chave e quer ligá-los e mantê-los agrupados, basta usar a função cogroup. Desta forma, será evitada toda a sobrecarga associada a descompactar e compactar os grupos.
Use a função coalesce se diminuir o número de partições do RDD em vez de repartition. O coalesce é útil porque evita um shuffle completo uma vez que usa partições existentes para minimizar a quantidade de dados baralhados.
O Spark calcula o closure da tarefa antes de executar cada tarefa nos executores disponíveis. O closure é variáveis e métodos que devem estar visíveis para o executor executar os cálculos no RDD. Se houver uma matriz enorme acedida a partir do Spark Closures, por exemplo, alguns dados de referência, essa matriz é enviada para cada nó de Spark com closure. Por exemplo, se tivermos 10 nós em cluster com 100 partições (10 partições por nó), esse Array será distribuído pelo menos 100 vezes (10 vezes para cada nó). Se a transmissão for usada, será distribuída uma vez por nó através de um protocolo P2P eficiente. Depois do valor ser transmitido para os nós, não pode ser alterado para garantir que cada nó tenha a mesma cópia de dados. O valor modificado pode ser enviado para outro nó posteriormente, o que daria resultados inesperados.
Se o RDD pequeno for pequeno o suficiente para caber na memória de cada Worker podemos transformá-lo numa variável de broadcast e transformar toda a operação numa junção lateral do Map para o RDD maior e, dessa forma, o RDD maior não precisa de ser shuffled. Isto pode acontecer facilmente se o RDD menor for uma tabela de dimensão.
Se o RDD de tamanho médio não couber totalmente em memória, mas o conjunto de chaves cabe, é possível explorar isto. Como um join descarta todos os elementos do RDD maior que não tenham correspondência no RDD de tamanho médio, pode ser usado o conjunto de chaves médio para fazer isso antes do shuffle. Se houver uma quantidade significativa de registos que são descartados desta forma, o shuffle resultante irá transferir muito menos dados. É importante observar que o ganho de eficiência depende da operação filter, reduzindo o tamanho do RDD maior.
A menos que o nível de paralelismo para cada operação seja alto o suficiente, os clusters não serão totalmente utilizados. O Spark define automaticamente o número de partições de um input de acordo com seu tamanho e para distribuições de shuffle. O Spark cria uma partição para cada bloco no HDFS com 64 MB por default. Ao criar um RDD, é possível passar um segundo argumento como um número de partições, por exemplo:
val rdd= sc.textFile(“file.txt”,5)
A declaração acima criará um RDD de textFile com 5 partições. O RDD deve ser criado com o número de partições igual ao número de cores no cluster para que todas as partições sejam processadas em paralelo e os recursos também sejam usados da mesma forma.
Os DataFrames criam um número de partições igual ao parâmetro spark.sql.shuffle.partitions. O valor default de spark.sql.shuffle.partitions é 200.
yarn.nodemanager.resource.memory-mb = ((Node’s Ram GB – 2 GB) * 1024) MB
Número total de cores de um nó = yarn.nodemanager.resource.cpu-vcores
Para o executorMemory, a alocação de memória é baseada no algoritmo:
Runtime.getRuntime.maxMemory * memoryFraction * safetyFraction, where memoryFraction = spark.storage.memoryFraction e safetyFraction = spark.storage.safetyFraction.
Os valores default de spark.storage.memoryFraction e spark.storage.safetyFraction são respectivamente 0.6 e 0.9, portanto o executorMemory real é:
executorMemory = ((yarn.nodemanager.resource.memory-mb – 1024) / (Executor (VM) x Node +1)) * memoryFraction * safetyFraction.
Considere o seguinte exemplo:
3 Worker nodes e um Application Master Node cada um com 16 vCPUs, 52 GB de memória:
yarn.nodemanager.resource.memory-mb = (52 – 2) * 1024 = 51200 MB
yarn.scheduler.maximum-allocation-mb = 20830 MB (tem de ser maior do que executorMemory)






