
7 Março 2024
Abordagem ao Modern Data Stack

Em que pontos de negócio está cego? Qual o potencial dos dados que não está a armazenar? Que relação, a curto e a longo prazo, pretende com a tecnologia que pode remover esses pontos cegos – confiar num fornecedor, numa empresa de consultoria, ou em pessoal interno?
TL;DR: não há um caminho (fácil), ou não teriamos emprego.
Com a abundância de fontes de dados – desde ERPs, CRMs aos meios de comunicação social e IoTs, até start-ups e empresas não tecnológicas compreendem o valor da análise de dados e dos serviços em cloud na retenção e aquisição de novo negócio através de uma melhor compreensão dos seus clientes, do potencial para processos internos mais rentáveis e, do potencial de automatização na sua organização. No entanto, estas organizações mais pequenas – ou menos conhecedoras de tecnologia – serão cautelosas em assumir o desenvolvimento e manutenção de workloads em que não são especializadas, e confiarão numa empresa de consultoria (como nós!) para desenvolver e manter as suas workloads, e podem decidir usar essa iniciativa para fazer crescer a sua equipa internamente, participando ativamente no desenvolvimento, e potencialmente assumir algumas, se não todas, as futuras manutenções e desenvolvimentos.
Como especialistas em Data Analytics, cada cliente novo significa mergulhar profundamente no seu negócio para ajudar a construir um roadmap de analytics que entregue valor a curto prazo, mas que esteja também alinhado com uma visão a longo prazo da organização, considerando a sua cultura, competências, objetivos, compromissos e a guie na escolha dos processos, tecnologia e desenvolvimento corretos.
Estando a metodologia de desenvolvimento alinhada, como escolher as ferramentas? Alguns pontos importantes:
Então, como poderia ser uma arquitetura de dados em managed services no início?
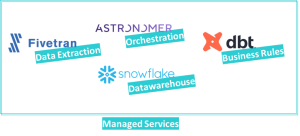
Começando com o Datawarehouse – há uma boa concorrência no mercado – Snowflake, Amazon Redshift, Google BigQuery são os serviços populares, e oferecem uma gama diferente de características e opções de preços, por isso é fundamental compreender quais as características de que realmente precisa e determinar o seu padrão de utilização para avaliar a tecnologia certa para si.
Para criar e manter os seus modelos de negócio DBT é uma boa escolha – essencialmente, é uma framework para criar modelos SQL com características tais como data testing, data lineage, documentação, controlo de versão e camadas de abstração que tornam o seu projeto modular e flexível – de facto, um projeto DBT bem desenvolvido promoverá a substituição de tecnologias de Datawarehouse no futuro, uma vez que reduz consideravelmente o esforço de retrabalho.
A própria DBT é um projeto open-source, mas existe uma oferta Cloud com preços competitivos para uma pequena equipa de desenvolvimento – tudo sem a necessidade de se preocupar com o hosting!
Se utiliza dados de outra equipa ou departamento e já se encontra num armazenamento que pode ser referenciado pelo seu Datawarehouse (tais como Amazon RDS, Amazon S3, Azure Storage Account ou Google Cloud Storage, etc.) então parabéns, pois a sua arquitetura de dados backend pode começar apenas com estas duas ferramentas. No entanto, a maioria dos projetos exigirá a extração de novos dados, caso em que poderá utilizar um managed service como Fivetran ou Stich, que se encarregará do alojamento e manutenção dos conectores, basta escolher a fonte, o alvo e pay per use.
Se começar a enfrentar pedidos como – “Quero que modelos específicos sejam atualizados logo após a extração e carregamento de certos dados”, ou “Quero adicionar fontes personalizadas que a minha ferramenta de extração não suporta” ou “Preciso de alguns passos automatizados personalizados para ligar alguns processos durante o processo ELT”, então poderá precisar de adicionar uma outra camada ao seu ecossistema, um orquestrador flexível que possa supervisionar todo o processo e preencher potenciais lacunas em falta, como o Astronomer – que é essencialmente uma versão gerida do Apache Airflow.
Muitas outras managed tools estão disponíveis no mercado para vários casos de utilização, tais como catalogação, testes, monitorização, que podem ser adicionadas a esta arquitetura. Quanto mais aplicações acrescentar, mais difícil será gerir os seus desenvolvimentos, integrações e deployments, uma vez que cada ferramenta pode ter a sua própria abordagem.
Se a frase seguinte fizer sentido para si – “Os meus pedidos de características empresariais estão a crescer, assim como a minha equipa de desenvolvimento e o tamanho das workloads, levando-me a níveis mais elevados de managed service que talvez seja demasiado caro – quero assumir parte da manutenção internamente e personalizar a minha arquitetura de acordo com as minhas necessidades exatas” – então a arquitetura seguinte visa abordar esse aspeto:
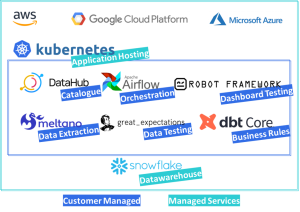
O primeiro objetivo é estabelecer uma boa infraestrutura de base em qualquer uma das clouds, que possa escalar, seja bem adotada, permita o alojamento de qualquer aplicação, e tenha eficiência de recursos – Kubernetes é o padrão para cumprir estes requisitos (é como a maioria dos managed services funcionam no backend), uma vez que irá alojar as suas aplicações, partilhar recursos de cloud entre elas para eficiência e assegurar a comunicação entre as aplicações e o mundo exterior.
Não precisa de gerir “Kubernetes puros”, pois cada cloud tem o seu próprio managed service para Kubernetes, para que parte da manutenção seja assegurada pelo fornecedor da cloud (como cada managed service – por uma pequena taxa) e pode adicionar as suas workloads agnósticas de Cloud no interior – um bom compromisso entre personalização, preço, características e manutenção.
Após a instalação da infraestrutura de base, poderá então instalar as aplicações de que necessita, tais como Apache Airflow, DBT Core, entre outras – e refatorar as workloads anteriores dos managed services para a nova arquitetura – se os serviços geridos forem escolhidos com um roadmap como este em mente, o refator das regras de negócio e orquestração de processos será fortemente reduzido.
Alguns benefícios desta arquitetura são o preço a uma maior escala, a facilidade de criar múltiplos ambientes rápida e dinamicamente conforme necessário – tais como múltiplos dev environments (um para cada desenvolvimento ou desenvolvedor) e um verdadeiro pre-prod environment para melhores testes e processos UAT – e um pipeline CI/CD mais centralizado.
Há muito mais considerações que precisam de ter lugar antes de se comprometer com uma arquitetura, uma vez que cada cliente terá as suas próprias exigências e bloqueios únicos. No entanto, um tema comum é que as equipas empresariais querem novas funcionalidades entregues cada vez mais rapidamente, o mercado de análise de dados está a evoluir rapidamente, e novas e melhores ofertas estão continuamente a ser lançadas, pelo que a importância de ser adaptável neste mercado é maior do que nunca.






